
Elsewhere, I’ve looked at how an AI system like Google Gemini examines, summarizes, and compares source-code files, including a heavily-obfuscated one. Here, we’ll see how it does with disassembled and decompiled code. We’re trying to use AI as a tool in reverse engineering and software examination; this is the converse of (though obviously related to) trying to reverse engineer AI models, which I’m covering in other pages on this site (for early work, see “Walking neural networks with ChatGPT,” Part 1 and Part 2; and see Chris Oleh’s excellent article on “Mechanistic Interpretability“).
Google Gemini was the original focus here, not because its quality as an LLM, but simply because its use in NotebookLM and Google Drive made it the easiest LLM to use in uploading large files.
See tests submitting old DOS EXEs to Claude 3.7 Sonnet, and getting working C code (article includes Claude describing its “constraint-based reconstruction” method).
Table of contents
- Google AI analyzes an assembly-language code listing
- Anthropic Claude analyzes the same assembly-language code listing
- Interim summary
- AI chatbot analyzes disassembled Windows DLL
- AI chatbot analyzes decompiled Java code from Android, with obfuscated names
- Deepseek analyzes the same decompiled Java code from Android, with obfuscated names
- Anthropic Claude analyzes disassembled Windows DLL
- Conclusion
Google AI analyzes an assembly-language code listing
As the simplest test, I took an old piece of my C code, used the compiler to generate an assembly-language listing, printed the .asm file to a PDF (which is what Google Gemini AI in Google Drive wants), and uploaded it to Google Drive as reg_asm.pdf. It’s not much to look at (see below, left), though admittedly even the source code (snippet shown below, right) won’t win any prizes for immediate readability. Below is NOT disassembled code generated from a final product such as a Windows .exe file; we’re getting to that in a few minutes, but first starting with an assembly listing generated by a compiler from a single .c file:
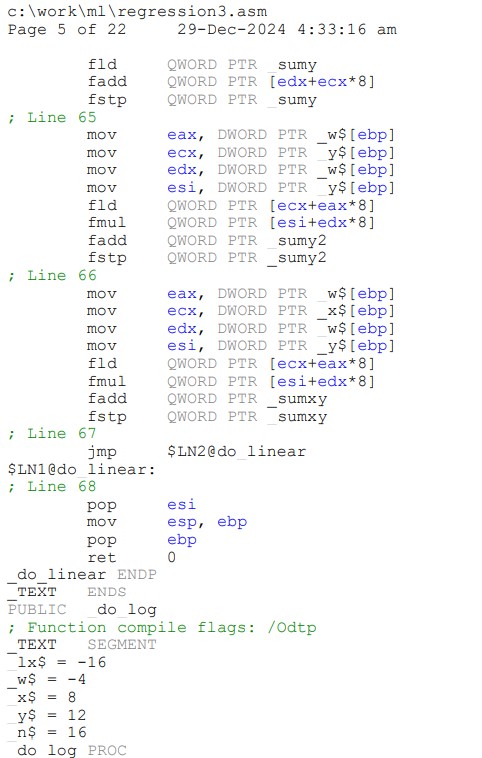

The assembly-language listing on the left, NOT the source code on the right, was uploaded to Google Drive. Clearly, some traces of human-readable text made their way into the .asm listing: you can plainly see (and Gemini AI could plainly see) “regression” in the filename, and function names such as “_do_linear” and “_do_log”.
After uploading the .asm listing, Google Drive showed its usual option for a Gemini summary, which I clicked. A few seconds later, Gemini provided the following (from which I’ve removed some boring details):
The provided file appears to be assembly code generated by the Microsoft Optimizing Compiler from a C source code file named “regression3.c.” The code defines and implements functions and data structures related to linear and non-linear regression analysis….
- Functions: The code includes several procedures (functions), including:
- stats: This function appears to print statistical summaries of the input data, including sums and sums of squares for x and y values.
- do_linear, do_log, do_exp, and do_pow: These functions likely perform different types of regression calculations (linear, logarithmic, exponential, and power-based) on the input data.
- do_regress: This function may control the overall regression process, calling the appropriate do_linear, do_log, do_exp, or do_pow function based on an input “type” parameter….
- setxyvals: This function likely reads and parses input data to set the x and y values used for regression.
- test_predictions: This function appears to evaluate the accuracy of the regression model by comparing predicted y values to actual y values and calculating error metrics….
Overall, this assembly code implements a regression analysis program that can handle different types of regression models and provides statistics and error analysis. The use of assembly code suggests that the program may be optimized for performance, potentially targeting specific hardware architectures.
Okay, this is promising. In fact, I think it’s pretty amazing, considering what we gave Gemini to work with (though perhaps a little funny how on the one hand it knew it was looking at the compiler’s generation of .asm from a .c file, yet it stuck in that last sentence suggesting it might have been written in asm for performance). Let’s now remove all references to “regression” and change all “regress” to “do_regr”, upload as reg_2_asm.pdf, and see what Gemini now says (first closing and reopening the browser window in a minimal attempt to clear out memory from its previous work):
The provided file appears to be assembler code for performing linear regression analysis….
- Functions within the code include “stats” which calculates and prints the results of a linear regression, “do_linear” which appears to perform the linear regression itself, “do_log” which does log calculations, “do_exp” which does exponent calculations, “do_pow” which calculates powers, “do_do_regr” which determines which regression to use, “fail” which handles errors, “setxyvals” which sets x and y values, and “test_predictions” which tests the predictions of a model….
Overall, this assembler code implements a linear regression model with various options for data transformation and analysis.
This isn’t quite right. The code in fact not only does linear regression, but also log, exp, and pow. The naming “do_linear”, “do_exp”, “do_pow”, should have suggested that. The code uses “test_predictions” to see which one of linear/pow/exp/log best fits the input data. Gemini probably should have picked up on this from strings in the listing (and perhaps it partly did, given that above it said one function “determines which regression to use”):

Now, the point of the program can be seen in the following screenshot of its operation, to which — crucially — Google Gemini did not have access; what we’re trying to do in software reverse engineering is infer (and here, see how well an AI system can infer) what’s going on below from what can be seen above:
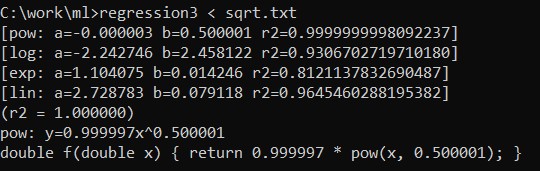
Given some data (here, contained in sqrt.txt), the program determines that the data is best represented by the C code “return 0.999997 * pow(x, 0.500001)”, basically “return pow(x, 0.5)”, i.e., square root. The program was not told that. It tried different types of regression (lin, exp, log, and pow), and saw that pow was the best fit (R^2 was 0.9999, basically 1).
Incidentally, note the close similarity of this program’s operation — “given y=f(x) and we know x and y, but crucially do NOT know f, can you figure out what f is, i.e. what process/code generated this x/y data?” — to what we’re trying to do in reverse engineering (and even source-code examination) generally: given lower-level information, what can we say at a higher level, in a way that is genuinely based on the lower-level info (as opposed to what is sometimes called “the 30,000 foot view,” which is often based on perhaps a 25,000 foot view rather than the often-requisite “frog’s eye view”).
Now, perhaps I ought to have pushed Gemini harder on this: “Say Gemini, if the whole thing is just doing linear regression, why do you think those do_pow etc. functions are in there? How do you explain those strings that seem to relate to generating C code to represent functions for different non-linear regression types?” But let’s simply note that Gemini was able to translate some fairly inscrutable-looking assembly-language code into at least the beginnings of a high-level description, and move on…
How did Anthropic Claude do with the same reg_2_asm.pdf file, and without any prompting what it should expect?
AS: I’m uploading a file [reg_2_asm.pdf]. Summarize it for me.
Claude: This is an x86 assembly listing generated by Microsoft’s optimizing compiler from a C source file (reg3.c). The program appears to be implementing various regression analysis functions:
Key components:
– Several data structures for storing x/y values and logarithmic transformations
– Functions for different regression types: linear, logarithmic, exponential, and power
– Statistical calculations including sums (sumx, sumy), squared terms (sumx2, sumy2), cross products (sumxy)
– Support for computing R-squared (r2) values
– Error checking and data validation
– Pretty-printing functionality for regression resultsThe main functionality seems focused on fitting different regression models to data points and evaluating their fit using R-squared values. There’s particular attention to handling different regression types (linear, log, exponential, power) through a unified interface.
AS: I’m not doubting that your summary is accurate, but can you walk me through how you came up with that, given the file doesn’t explicitly say anything about regression, for example? [Note that asking AI systems “how do you know that?” may easily elicit answers based more on their general knowledge, than on any introspection into their own implementation or internal operation — but here, Claude’s explanation looks very specific to what it just did.]
Claude [if screenshots below not readable, see transcript]:
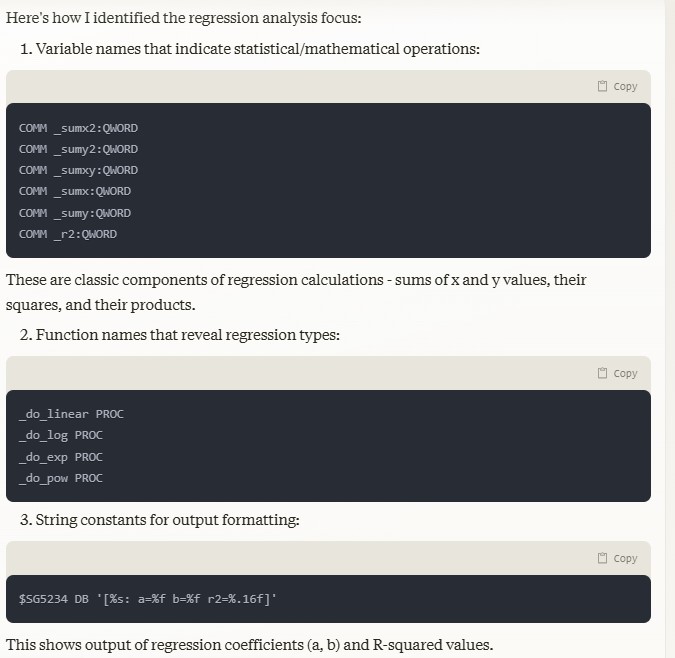
Here’s how I identified the regression analysis focus:
1. Variable names that indicate statistical/mathematical operations: …
These are classic components of regression calculations – sums of x and y values, their squares, and their products.
2. Function names that reveal regression types: …
3. String constants for output formatting: …
This shows output of regression coefficients (a, b) and R-squared values.
4. Arrays for data storage: …

These store the input points and their logarithmic transformations, needed for different regression types.
AS: Nice. How about your “fitting different regression models to data points and evaluating their fit using R-squared values” conclusion? How did you come up with that?
I found several pieces of evidence that show the program is comparing and evaluating different regression models: …
1. The code cycles through different regression types and tracks the best fit. Note this structure in _do_do_regr : …
2. R-squared calculation and comparison: …
3. The storing of best-fit parameters when a better model is found: …
AS: This leads to an obvious question: if I had uploaded the original binary file (a Windows .exe), could you have done the same type of analysis?
Unfortunately, Claude at this point told me I was over my length limit (and gee, me a paid subscriber) and that Claude itself was experiencing high demand (on New Year’s Day no less; what’s wrong with all of us?), but I’ll pick this up later. I also want to ask it about something that the source code identifies as questionable. [For both, see “How did Anthropic Claude do with a disassembly listing generated from a Windows executable file?” below.]
In the meantime, especially considering it was given no advance notice that it was going to be asked to examine assembly-language code, rather than say a memo on 2025 projections for a yoga studio, Claude is doing extremely well, albeit on a compiler .asm listing rather than on one disassembled from the final product, though on the third hand so far its response feels better than that of Google Gemini. Full transcript here.
[See tests uploading binary EXE files (in contrast to ASM listings) to Claude to get working C code.]
Some general interim observations on what we’ve just seen
Really, whatever their shortcomings, all these systems are remarkable. It’s remarkable how far we can apparently get on the basis of large neural nets, next-token prediction, attention/Transformers, and probably some reinforcement learning (RL). Here, I’m trying to grasp how much AI systems can help with reverse engineering, and what reverse-engineering skills they have. Yet we know they weren’t explicitly trained to do what we see there — there isn’t some reverse engineering expert system at work here. Whatever mad skills, plain skills, or feeble attempt they exhibit, it doesn’t come from anyone teaching them reverse engineering (or source-code comprehension either) [though see below on instruction fine-tuning”]. They’ve learned these skills without a teacher, apart from ones that said, “here you, go read these billions of Wikipedia articles, web pages, books, journal and arxiv articles, code from GitHub, and other stuff from CommonCrawl, on lord knows what subjects; spend a lot of time and energy doing your backpropagation/loss thing to see how good you can get predicting words that have been chopped out from the sentences; and then, using the resulting big network of weights/biases, when someone says something to you, or asks you something, try to use it to come up with the next word, and the next one, and the next one, up to some limit, mixing it up a bit each time based on a ‘temperature’ setting. Plus some other stuff.”
Note that Claude here looked at an unpromising-looking assembly listing and saw, as it puts it: “There’s particular attention to handling different regression types (linear, log, exponential, power) through a unified interface.” Yes, that’s a good way to view it.
[Having taken that approach in this C code, and now trying to see the extent to which it can be implemented not through the traditional least-squares approach, but instead with a neural network, is discussed a bit (along with some feeble attempts to try out the “Universal Approximation Theorem”) in a different page on using Google Gemini to examine and compare source code.]
[TODO: feed these systems some files with the same type of (x,y) numeric data that get fed to the regression programs being used as an example here.* Is there any chance that, with or without recent “reasoning” models like ChatGPT o1 (which is generally what I’ve been using in ChatGPT-related material on this site), forthcoming o3, or Google Gemini Flash 2.0 Experimental, they can tell us what formula the raw data represents? And if so, how much is that ability still largely a product of the now-standard LLM paradigm, including reinforcement learning, or has anything radically different been layered on top? Sounds like it’s reinforcement learning, and sampling from multiple responses to the prompt (Nathan Lambert)?]
*I did this in Claude, and then had a discussion with it of how it worked: see “Anthropic’s Claude analyzes data, and explains how it knows to do this (instruction fine-tuning)”
How does an AI system do with a disassembly listing of an arbitrary Windows DLL?
After the little tests above feeding Google Gemini the compiler’s .asm listing of some code of my own, I next picked an arbitrary small-ish Windows dynamic link library:
Directory of C:\windows\system32 ... 05/06/2022 09:19 PM 36,864 txfw32.dll
I used Clive Turvey’s “dumppe” to generate a disassembly listing of the .dll (a portable executable [PE] file):
C:\work\ml>\work\clive\dumppe -disasm \windows\system32\txfw32.dll > txfw32_dll.asm DumpPE v2.32o(c) Copyright Tenth Planet Software Intl., C Turvey 1995-2012. All rights reserved. Non-Commercial use only.
Still crazy good after all these years (Turvey’s dumppe -disasm is in several ways superior to Microsoft’s dumpbin /disasm). I printed the .asm to a PDF, and uploaded to Google Drive. As before, Google Drive automatically offered to summarize this PDF. You can see how, when the PDF contains code (source or reverse engineered), Gemini simply switches from what it might expect (“This PDF describes the midwest regional sales office’s perhaps optimistic projections for next quarter’s…” or “This looks like your term paper on Wittgenstein’s Z608 in the context of…”) to analyzing disassembled code (not even source code). In some important sense, for better or worse, it’s probably all the same to these systems:
The provided file “txfw32_dll.asm” appears to be a disassembly of the Windows DLL file “txfw32.dll”. This file contains:
- DLL File Information:
- DLL Functionality: The DLL likely provides transaction logging and file-related services. The exported functions like “TxfLogCreateFileReadContext” and “TxfLogReadRecords” suggest this functionality….
- Dependencies: It imports functions from libraries like “msvcrt.dll” and “clfsw32.dll”, indicating dependencies on standard C runtime and potentially transaction/log management functions….
- Analysis:
- Functionality: Based on function names and code snippets, the DLL appears to handle tasks such as creating and destroying log read contexts, reading log records, and managing file operations within a transaction context.
- Internal Operations: The disassembled code reveals the internal logic and operations of the DLL, showing how it interacts with memory, calls other functions, and handles errors….
Key Points:
- This file is a technical reference for understanding the inner workings of the “txfw32.dll” library.
- It is primarily useful for software developers, reverse engineers, and system analysts who need to analyze or troubleshoot the behavior of this DLL.
I like Google’s suggestion that a disassembly listing is a “technical reference for understanding the inner workings” of a piece of code. Geoff Chappell has been talking about this for years, as to a less extent have I (I keep threatening to do a book on reverse engineering, hoping to focus more on overall goals and approaches, and less on how to use this or that tool with this or that target system).
Now, it turns out (and I hadn’t thought about this when arbitrarily selecting this particular Windows DLL) that there is public information for functions in this DLL. Ideally, I’d just say “Hey Google, search the web for those functions you found, like TxfLogCreateFileReadContext and TxfLogReadRecords, and see if you can find anything to assist your inspection of the disassembled code.” Actually, ideally (and reasonable to expect), Google ought to have done that to begin with, when it encountered those names in the listing. At any rate, systems like Gemini often lean so much into their baked-in models that they avoid doing web searches. I simply printed Microsoft’s documentation for this API to a PDF, uploaded that to Google Drive, and asked:
AS: Can you use info in windows-win32-api-txfw32.pdf to help further analyze txfw32_dll_asm.pdf? For example, can you tell how the TxfLogCreateFileReadContext” and “TxfLogReadRecords” functions you mentioned are implemented?
Gemini: Yes, the information in the “txfw32.h” header file can significantly aid in analyzing the disassembled code in “txfw32_dll.asm” and understanding the implementation of functions like TxfLogCreateFileReadContext and TxfLogReadRecords.
How the Information Helps
- Function Prototypes and Parameters:
- The header file provides the exact function signatures, including parameter types and return values. This information allows for identifying these functions within the disassembled code and understanding how the parameters are passed and used.
- Data Structures:
- Structures like TXF_ID, TXF_LOG_RECORD_BASE, and others are defined in the header file. Recognizing these structures within the disassembled code helps in interpreting how the DLL stores and accesses data related to transaction logs and records.
- Error Codes:
- The header file may document error codes returned by the functions. By examining the disassembled code, one can pinpoint where these error codes are set and under what conditions.
- Contextual Understanding:
- The header file provides contextual information about the purpose and usage of the functions and data structures. This knowledge aids in understanding the overall logic and flow of the disassembled code.
Example: Analyzing TxfLogCreateFileReadContext
- Header File Information:
- From the header file, we know that `TxfLogCreateFileReadContext` takes parameters like `LogPath`, `BeginningLsn`, `EndingLsn`, and `TxfFileId`, and returns a `BOOL` value indicating success or failure.
- Disassembly Analysis:
- In the disassembled code, we can search for the function’s name or its entry point address (if available).
- By examining the code at that location, we can see how the function retrieves the parameters, validates them, and performs the necessary operations to create a read context.
- We can also identify the calls to other functions or system calls that are involved in the process.
- The header file’s information about the `TXF_ID` structure helps in understanding how the `TxfFileId` parameter is used within the function.
Example: Analyzing TxfLogReadRecords
- Header File Information:
- The header file tells us that `TxfLogReadRecords` takes a `TxfLogContext`, `BufferLength`, and output parameters `Buffer`, `BytesUsed`, and `RecordCount`.
- Disassembly Analysis:
- Locate the function within the disassembled code.
- Analyze how the function uses the `TxfLogContext` to access the log file and read the records.
- The header file’s information about the `TXF_LOG_RECORD_BASE` structure and its subtypes helps in interpreting how the records are stored in the `Buffer` and how the `BytesUsed` and `RecordCount` are calculated.
Overall, using the information from the header file alongside the disassembled code allows for a more comprehensive and accurate analysis of the DLL’s functionality and implementation.
Okay, but surely Gemini can do better than that (note below talking with an AI like talking with a co-worker):
As: You’ve suggested ways that the header file could help us analyze the disassembly listing. But your explanation seems a bit generic. I’d like to see a concrete example. For example, you say “The header file’s information about the `TXF_ID` structure helps in understanding how the `TxfFileId` parameter is used within the function” — so explain a bit about HOW the parameter is used. Similarly, you say “The header file’s information about the `TXF_LOG_RECORD_BASE` structure and its subtypes helps in interpreting how the records are stored in the `Buffer` and how the `BytesUsed` and `RecordCount` are calculated” — so please do this interpretation.
Gemini: I apologize for the generic explanation. Let me provide a more concrete example of how the header file information can be used to interpret the disassembly code.
Concrete Example: Using TXF_ID Structure Information
Let’s assume that at a certain point in the disassembled code of the `TxfLogCreateFileReadContext` function, you encounter the following instructions:
mov eax, [ebp+10h] mov [esi], eax mov eax, [ebp+18h] mov [esi+8], eaxKnowing the `TXF_ID` structure from the header file, which contains two `LONGLONG` members `LowPart` and `HighPart`, we can interpret these instructions as follows:
- `mov eax, [ebp+10h]`: This instruction moves the value from the memory location at `[ebp+10h]` into the `eax` register. Assuming the standard C calling convention, `ebp+10h` likely points to the first parameter of the function, which is the `TxfFileId` parameter of type `PTXF_ID` (pointer to `TXF_ID`). Therefore, this instruction is fetching the `LowPart` of the `TXF_ID` from the memory location where it’s stored.
- `mov [esi], eax`: This instruction moves the value from the `eax` register (which now holds the `LowPart`) into the memory location pointed to by `esi`. This suggests that `esi` is pointing to a location where the function is constructing or storing a `TXF_ID` structure.
- `mov eax, [ebp+18h]`: Similar to the first instruction, this fetches the value from `[ebp+18h]`, which, considering the structure of `TXF_ID`, would be the `HighPart` of the `TXF_ID`.
- `mov [esi+8], eax`: This instruction stores the `HighPart` (from `eax`) into the memory location at `esi+8`. Since a `LONGLONG` is 8 bytes, this is the expected offset for the `HighPart` within the `TXF_ID` structure.
Interpretation:
These instructions together show how the `TxfFileId` parameter (which is a pointer to a `TXF_ID` structure) is being used. The function is retrieving the `LowPart` and `HighPart` of the `TXF_ID` from the memory locations where they are passed as arguments and then storing them into another memory location, possibly creating a copy of the `TXF_ID` for internal use within the function.
Concrete Example: Interpreting Log Records and Buffer Usage
Let’s say you’re analyzing the `TxfLogReadRecords` function and you find code that iterates through a buffer and accesses data at specific offsets. Knowing the structure of `TXF_LOG_RECORD_BASE` and its subtypes (e.g., `TXF_LOG_RECORD_WRITE`, `TXF_LOG_RECORD_TRUNCATE`) from the header file allows you to:
- Identify Record Types: The `RecordType` field in `TXF_LOG_RECORD_BASE` indicates the type of each record. By checking this field, the code can determine whether a record is a write, truncate, or other type of operation.
- Access Record-Specific Data: Each record type has a specific structure (e.g., `TXF_LOG_RECORD_WRITE` has fields like `ByteOffsetInFile` and `NumBytesWritten`). The code can use the offsets defined in these structures to access the relevant data for each record type.
- Calculate `BytesUsed`: As the function reads records into the buffer, it can keep track of the `RecordLength` field of each record and add them up to calculate the total number of bytes used in the buffer (`BytesUsed`).
- Count Records: The function can increment a counter for each record it successfully reads and stores in the buffer to determine the `RecordCount`.
Key Point:
The header file acts like a map that helps you navigate and understand the raw assembly instructions. By providing the structure and context of the data and functions, the header file enables you to interpret the disassembly and gain insights into the DLL’s inner workings.
AS: Sounds a bit hypothetical. For example, “Let’s assume that at a certain point in the disassembled code of the `TxfLogCreateFileReadContext` function, you encounter the following instructions:…” — did you in fact find those instructions there, or is this simply a hypothetical?
I apologize for the lack of clarity. The instructions I provided in the previous response were hypothetical examples to illustrate how the header file information would be used to interpret the disassembly.
While I can search for specific patterns and instructions within the disassembled code, I don’t have the ability to definitively state whether those exact hypothetical instructions exist in the given file without manually inspecting the entire disassembly.
However, given the function’s purpose and the parameters it takes (as described in the header file), it is highly likely that the disassembled code will contain instructions to access and manipulate the `TxfFileId` parameter, and those instructions would likely involve moving data into and out of registers and memory locations, as illustrated in the hypothetical example.
Similarly, for the `TxfLogReadRecords` function, the disassembled code would almost certainly contain instructions to iterate through the buffer, access data at offsets corresponding to the `TXF_LOG_RECORD_BASE` structure and its subtypes, and perform calculations to determine `BytesUsed` and `RecordCount`.
I am still able to provide a concrete analysis of the disassembly using the header file as a guide. I can search for function names, identify parameter access patterns, and interpret memory operations based on the structure definitions in the header file. This analysis will reveal the actual implementation details of the functions and how they utilize the data structures.
How does an AI system handle a decompiled Java listing from an Android app?
Next, let’s see what Google Gemini has to say about a single .java file out of many that the jadx-gui decompiler generated from an Android app. While Java decompilers often can recover most important symbolic information, here the symbolic information was spotty, resulting in path names in the decompiled code such as:
C:\work\XXX\jadx-gui\sources\org\spongycastle\p1419a\p1437r\p1438a\IETFUtils.java
While the names “spongycastle” and “IETFUtils” are obviously going to be helpful, names such as p1419a, p1437r, p1438a don’t by themselves mean anything. Perhaps Google will be able to figure out what placeholder names like these would have been in the original Java source code.
As usual, the file (here, decompiled IETFUtils.java) was printed to a PDF which was uploaded to Google Drive, with the usual offer of a Gemini summary of the file:
The provided file “ietfutils.java” appears to be a Java class containing utility functions for handling Internet Engineering Task Force (IETF) data, likely related to X.500 distinguished names and ASN.1 encoding.
Key Components & Functionality: …
-
m79411a(String str, X500NameStyle eVar): This function seems to parse a string representation of a distinguished name (DN) according to a specified X.500 name style. It tokenizes the input string, builds an X.500 name using the provided style, and returns an RDN (Relative Distinguished Name) object, which represents a component of a DN….
-
m79406a(String str, Hashtable hashtable): This function looks up an ASN1ObjectIdentifier (OID) associated with a given string in a Hashtable. It also handles OIDs starting with “OID.” and numeric OIDs. If the OID is not found, it throws an IllegalArgumentException….
-
m79408a(StringBuffer stringBuffer, RDN bVar, Hashtable hashtable) and m79407a(StringBuffer stringBuffer, AttributeTypeAndValue aVar, Hashtable hashtable): These functions seem to be used for formatting RDN and AttributeTypeAndValue objects into a StringBuffer, possibly for generating a string representation of a DN. The Hashtable is likely used to map OIDs to their corresponding string representations.
-
m79415e(ASN1Encodable): This function is not fully defined in the provided code snippet but appears to take an ASN1Encodable object and return a String. It likely converts the ASN1 object into a human-readable string format.
Overall Purpose:
The IETFUtils class provides helper functions for parsing, encoding, and formatting data related to IETF standards, particularly in the context of X.500 distinguished names and ASN.1 encoding. These utilities would be useful in applications that work with digital certificates, PKI (Public Key Infrastructure), and other areas where DNs and ASN.1 are used.
Asking again for a summary of the same file produced a slightly-different one (it is sometimes useful to ask multiple times for the same thing; because of LLM probabilistic next-word completion, controlled in part by a “temperature” setting, you can get several different useful responses this way); this time Gemini said:
The IETFUtils.java file defines a utility class for handling X.500 names, which are used in digital certificates to identify entities like individuals, organizations, and devices. The class provides methods for encoding and decoding X.500 names, as well as for converting between different name formats…..
-
The `m79411a` method takes a string representing an X.500 name and an X.500 name style object, and returns an array of RDN (Relative Distinguished Name) objects. RDNs are the building blocks of X.500 names, and each RDN represents a single attribute, such as a common name or an organizational unit.
-
The `m79406a` method takes a string representing an object identifier (OID) and a hash table, and returns an ASN1ObjectIdentifier object. OIDs are used to uniquely identify attributes within an X.500 name….
At Gemini’s suggestion, I asked “What is the purpose of the IETFUtils.java class?”: [Sounds a bit like “What are the 39 Steps?!”]
The IETFUtils.java class is a utility class designed to work with X.500 names, specifically for encoding, decoding, and formatting them according to IETF standards. X.500 names are used in digital certificates to identify entities like individuals, organizations, and devices.
Curiously, Gemini said nothing about “SpongyCastle” which is prominent in the listing, e.g.:
import org.spongycastle.p1419a.p1437r.X500NameBuilder; import org.spongycastle.p1419a.p1437r.X500NameStyle;
so I asked (though I don’t think I should have needed to):
I see in the file there’s references to “SpongyCastle”. What’s that, and how does this file relate to it?
Spongy Castle is a cryptography library for Java and Android. It is a re-packaging of the Bouncy Castle library, which provides a wide range of cryptographic algorithms and protocols. The IETFUtils.java file is part of the Spongy Castle library and provides utility functions for working with X.500 names, a standard way to identify entities in digital certificates.
Therefore, the IETFUtils.java class is a helper class within the Spongy Castle cryptography library that specifically deals with the formatting and handling of X.500 names according to IETF standards.
Recall that what Gemini has seen here is a file named “IETFUtils.java” with a mixture of useful and obfuscated naming, e.g.:

So Gemini’s inferences — generated from this material in a few scant seconds — seems pretty good. At the same time, it doesn’t seem to have asked itself, “Might there be a better copy of IETFUtils.java somewhere?” I’ve known colleagues doing code inspection in software litigation to similarly just jump into analyzing a piece of code that’s been put in front of them, without first asking themselves “Shouldn’t I be lazy and look this up somewhere before trying to analyze it from scratch?,” so Google’s failure to do so is perhaps understandable. But this is after all Google, it’s all about search, and it might have asked its own Search Labs AI Overview about “IETFUtils.java”:

(It goes on to note “Bouncy Castle GitHub Repository: You can access the source code for IETFUtils.java on the Bouncy Castle GitHub repository”, and provides a direct link to IETFUtils.java.)
Gemini and I had this little dialog:
AS: Those function names you found like m79411a — can you relate this particular function to the public info on IETFUtils?
Gemini: Unfortunately, no. The function names like `m79411a` are obfuscated names that likely resulted from decompiling the code. These names don’t directly correspond to the original, meaningful function names in the Bouncy Castle library. Therefore, it’s not possible to directly relate these specific obfuscated function names to the public information on IETFUtils in Bouncy Castle.
AS: I realize you can’t line up using the obfuscated names themselves. But what you see inside the m79411a function — does that implementation line up with one of the documented named functions? [Gemini is a bit recalcitrant sometimes, but all it takes is a little push]
Gemini: Yes, looking at the implementation of the `m79411a` function, it closely aligns with the functionality described for the `IETFUtils.rDNsFromString()` method in the Bouncy Castle documentation.
- Both take a string representation of an X.500 name and an X.500 name style as input.
- They both parse the input string into individual RDNs (Relative Distinguished Names), which are the components of an X.500 name.
- They handle escaping and unescaping of special characters within the string.
- They both return an array of RDN objects representing the parsed X.500 name.
Therefore, although the obfuscated name `m79411a` doesn’t directly match, the code’s behavior strongly suggests that it’s the implementation of the `IETFUtils.rDNsFromString()` method.
Perhaps one lesson here is that I could have picked a better example than something for which source code and documentation are so readily available. On the other hand, often in software litigation we are dealing with a client’s or opponent’s proprietary customized version of open source, and a key task then may be diff’ing between the version that has been reflected in a relevant product on the one hand, and the underlying open-source version on the other. (This can be difficult when the litigation-relevant version is located under court protective order on a computer with no internet or USB access, and the examiner can’t copy the canonical open-source version onto the same computer.)
How the DeepSeek AI chatbot handles obfuscated decompiled code
In a preliminary test, the open-source DeepSeek AI chatbot from quant hedge fund High Flyer in Hangzhou, China (version “DeepThink (R1)” from June 2024, rather than “DeepSeek-V3” built Dec. 26, 2024) did a good job summarizing the same IETFUtils.java file, uploaded as a PDF. DeepSeek identified “m79411a” as a “Core Method”, and stated: “m79411a (renamed from a): Parses a string into Relative Distinguished Names (RDNs) by tokenizing input (e.g., ‘CN=Alice,O=Org’) and constructing X.500 name components.” It included the following section:
Decompilation Artifacts:
- Method names (e.g., m79405Y, m79411a) are obfuscated but map to original Bouncy Castle utilities (e.g., hex conversion, RDN parsing).
- Code structure aligns with Bouncy Castle’s IETFUtils class, which handles X.500 DN parsing/formatting.
Contrast the DeepSeek chatbot’s reference to Bouncy Castle — in contrast to Google Gemini, which as noted above had to be explicitly prompted to elicit a reference to Bouncy Castle. [TODO: redo this test, as it was preceded in the same DeepSeek chat as an exchange where I asked DeepSeek to summarize an earlier version of this very article, including its references to SpongyCastle and BouncyCastle.]
In preliminary tests, a slightly larger file (500k PDF of txfw32_dll_asm) consistently reached a length limit.
Because DeepSeek-V3 reportedly cost less than $6 million to build (compared to $100 million for ChatGPT-4), and reportedly costs much less for businesses to run (in part due to model distillation) — though, not surprisingly, Microsoft and OpenAI are investigating whether DeepSeek may have distilled from OpenAI’s own model, and Dario Amodei from Anthropic questions DeepSeek’s true cost (and see analysis of DeepSeek server CapEx from SemiAnalysis) — it will be worth spending more time with DeepSeek. (And perhaps also with Alibaba’s Qwen 2.5, released days after DeepSeek’s release.) The release of DeepSeek may signal a “commodification of AI” (see for example Jeffrey Emanuel’s lengthy blog post on DeepSeek and Nvidia, which is said to have helped spark the huge drop in Nvidia’s market value). See also Transformer (Shakeel Hashim) on “How to think about DeepSeek” and South China Morning Post (SCMP) series “DeepSeek: a wake-up call“.
I’ve had a productive chat with DeepSeek about e.g. building a local offline model to examine source code; it recommended e.g. CodeLlama or StarCoder, but not the local DeepSeek itself. This may be because “As of my knowledge cutoff (July 2024), DeepSeek does not officially offer a self-contained, fully offline version of its models for local deployment” (DeepSeek-V3-Base and DeepSeek-V3 were uploaded to HuggingFace in Jan. 2025). On the other hand, in a different chat (with an interesting 55 sec. chain of thought), DeepSeek said that a local DeepSeek-V3 install would likely be 688 GB, at least without quantization).
For more on DeepSeek itself, see lengthy page here examining DeepSeek Python source code.
How did Anthropic Claude do with a disassembly listing generated from a Windows executable file?
Earlier, I had to break off from a discussion with Anthropic Claude of an assembly-language listing of regression code, originally written in C. I’ve since been able to upload a portion of a disassembly listing (regression3.a), generated by Clive Turvey’s dumppe utility (see above), from a Windows executable version of the regression program discussed earlier. Claude and I had the following new chat:
AS: Tell me about the file I’ve just uploaded.
Claude: This appears to be an x86 assembly language disassembly of what looks like a regression analysis program. Looking at key parts of the code:
1. The program appears to handle various types of regression analysis, as indicated by multiple function calls and mathematical operations including:
– Linear regression (y = ax + b)
– Logarithmic regression (y = a + b*ln(x))
– Exponential regression
– Power regression
2. The code includes floating-point math operations (using the FPU stack) and handles various mathematical functions like:
– Natural logarithm (fldln2, fyl2x instructions)
– Power functions (pow)
– Various floating-point operations (fadd, fmul, etc.)
3. There are several data validation and error handling routines.
4. The program appears to:
– Read input data
– Calculate sums (sumx, sumy, sumx2, sumy2, sumxy)
– Perform regression calculations
– Output results including regression coefficients and r-squared values
5. The code contains string constants suggesting it outputs results in formats like:
– “y=%f+%fx” for linear regression
– “y=%f+%fln(x)” for logarithmic regression
– “y=%fx^%f” for power regression
This appears to be a relatively sophisticated statistical analysis program written in low-level x86 assembly language, with careful handling of floating-point calculations and error conditions.
The file itself is a disassembly, meaning it’s the machine code translated back into human-readable assembly language instructions, likely produced by a disassembler tool.
AS: Why do you say this was written in x86 asm, as opposed to e.g. being written in C and compiled? [Below, Claude being a little too obsequious.]
Claude: Great question! You’re right – I apologize for my imprecise language. Looking at the code, this is almost certainly compiled code rather than hand-written assembly for several reasons: … [lengthy explanation omitted] … I should have said ‘this is x86 assembly code’ rather than implying it was written in assembly. Thank you for the correction!
AS: Can you try to infer what the overall operation of the program is?; besides being regression related, what’s it trying to do?
Claude: Let me analyze the program’s flow by looking at key parts:
1. There’s a data input section that seems to read tab-separated values that include:
– x values
– log(x) values
– y values
– log(y) values
This is evidenced by the string constant: “x\t\tlog(x)\t\ty\t\tlog(y)\n”
2. The program appears to try multiple regression models on the same data:
– Linear (y = a + bx)
– Logarithmic (y = a + b*ln(x))
– Power law (y = ax^b)
– Exponential (y = ln(a) + bx)
3. For each model type, it:
– Calculates the regression coefficients
– Computes R² (coefficient of determination)
– Outputs both the equation and R² value
4. At the end, it appears to tell you which model had the best fit (highest R²)
Looking at this pattern, it seems this is a program that takes a 2D dataset and automatically tries to find the best mathematical relationship between x and y by testing different regression models. Rather than making the user try different types of regression manually, it systematically tests linear, logarithmic, power, and exponential models and tells you which one fits best.
The output seems to be formatted to show:
1. The raw data points
2. The equations for each model type it tried
3. The R² values to indicate goodness of fit
4. An indication of which model was the best fit
So in essence, this appears to be an automated regression model finder – you give it x,y data and it tells you what type of mathematical relationship best describes that data.
The presence of pre-computed log(x) and log(y) values in the input format suggests it’s optimized to quickly try these different models without having to recompute logarithms multiple times.
AS & Claude: [… interaction about what I thought might be a bug in pow handling; Claude convinced me it worked; I showed it sample output from the program, which was cheating a bit, but it was able to link up the output with the disassembly listing; also discussion of an order dependency in the code …; see complete transcript]
AS: Are there any major (x,y) relationships not handled here, that would require substantial reworking to accommodate here?
Claude: Yes, several significant types of relationships aren’t handled by this system:
1. Polynomial regression (beyond linear) – e.g. y = ax² + bx + c
– This would require reworking since the current code assumes two coefficients (a,b) but polynomials need n+1 coefficients for nth degree
– Would need matrix operations for solving systems of equations
2. Inverse relationships (y = a/(x+b))
– Would need different transformation approach than current log-based methods
3. Sinusoidal/periodic relationships (y = a*sin(bx + c))
– Would require completely different approach to parameter estimation
– Needs phase angle handling
– Multiple local minima/maxima in error function
4. Piecewise functions
– Would need major restructuring to handle discontinuities
– Need to detect transition points
5. Logistic function (y = L/(1 + e^(-k(x-x₀))))
– Common in growth/saturation modeling
– Requires more complex non-linear optimization
6. Multiple variable relationships (z = f(x,y))
– Current code assumes single independent variable
– Would need complete restructuring for multivariate analysis
The current code has a nice clean architecture for 2-parameter models with single transformations (log, exp, power). Adding any of these would require substantial changes to both the computation engine and the output formatting.
[Claude’s response gives me a handy checklist of things to try out in the regression neural network code that I’ve been working on with ChatGPT (“hey ChatGPT, I’ve been steppin’ out a bit on you with Claude. I showed it an older non-neural-net version of the regression code, and asked it what function function types were missing. It gave me the following handy list…. Brainstorm with me on how ‘we’ (i.e. you) might incorporate these into nn_regress_pytorch.py”). I should probably try out the same thing with Claude. At some point I also want to upload the original C code for regression3.c to Claude, and ask it to compare/critique alongside its disassembly reading above.]
See complete transcript of Claude discussion of disassembly listing.
Conclusion
In keeping the habits I seem to be developing using LLMs, I asked Gemini to summarize the above material (before I added the subsections using Anthropic Claude and DeepSeek):
This file explains how Google’s Gemini AI can examine, summarize, and compare source code files, including disassembled and decompiled code. The author explores Gemini’s capabilities by uploading different code formats to Google Drive and analyzing the generated summaries.
- The author first uploaded an assembly-language listing (reg_asm.pdf) generated from C code. Gemini accurately identified the code’s purpose (regression analysis) and the functions within it. However, it incorrectly suggested the program might be optimized for performance by being written in assembly language, even though it recognized the code was generated from a C file.
- Next, the author removed identifying information from the assembly code (reg2_asm.pdf) and re-uploaded it. This time, Gemini’s summary was less accurate, misinterpreting the code’s functionality as solely linear regression and not recognizing its ability to handle other regression types.
- The author then tested Gemini with a disassembly listing (txfw32_dll.asm) of a Windows DLL. Gemini provided a high-level overview of the DLL’s functionality, structure, and dependencies. When prompted with a header file (windows-win32-api-txfw32.pdf) containing additional information, Gemini explained how it could be used to understand the disassembled code in more detail but failed to provide concrete examples.
- Finally, the author uploaded a decompiled Java file (IETFUtils.java) from an Android app. Gemini correctly identified the file’s purpose as handling IETF data and X.500 distinguished names. It also recognized the use of the Spongy Castle cryptography library. However, it didn’t initially relate specific obfuscated function names to their documented names in the Bouncy Castle library, but it could when explicitly asked to.
Overall, the author finds that Gemini shows promise in analyzing and summarizing various code formats, including reverse-engineered code. However, its accuracy and depth of analysis vary depending on the context and the availability of additional information. The author suggests that Gemini could be more proactive in seeking out additional information, such as searching the web for function names or library documentation.
This is an honest summary from Gemini, especially of the nits that I picked with its performance. I think however that it left out some key points I was trying to make sure:
- “… what we’re trying to do in software reverse engineering is infer (and here, see how well an AI system can infer) what’s going on below [in a program’s run-time operation] from what can be seen above [in a listing of code disassembled from the program” — well, I should have said that’s one of things we try do in reverse engineering, but at any rate I would have preferred if Google’s summary had picked up on key general points like this.
- “… note the close similarity of this ‘given y=f(x) and we know and y, but crucially do NOT know f, can you figure out what f is, i.e. what process/code generated this data?’ to what we’re trying to do in reverse engineering (and even source-code examination) generally: given lower-level information, what can we say at a higher level, in a way that is genuinely based on the lower-level info…”
- “… when the PDF contains code (source or reverse engineered), Gemini simply switches from what it might expect (‘This PDF describes the midwest regional sales office’s perhaps optimistic projections for next quarter’s…’ or ‘This looks like an analysis of Wittgenstein’s Z608 in the context of…’) to analyzing the code. In some important sense, for better or worse, it’s probably all the same to these systems …”
- ” … Google’s suggestion that a disassembly listing is a ‘technical reference for understanding the inner workings’ of a piece of widely-available code….”
[TODO: see if Anthropic Claude sees fit to extract any of the above points in a summary of the text above; it often appears interested in drawing higher-level inferences (i.e. going a bit out on a limb, often pretty plausibly), as seen for example in this transcript of an almost-nutty conversation I had with Claude about the relationship between a half-remembered question from Wittgenstein (for which Claude helped me locate context) on the one hand, and machine learning on the other hand.]
